Detection and Segmentation
在这一小节,我们将讨论分割、定位、检测。
语义分割(Semantic Segmentation)
在下面这张图中,我们想用标记策略去标记每一个像素点。

在上图右边,语义分割不会去区分一个实例,仅仅关心像素点。
使用一个滑动窗口,采用一个小的窗口大小在整张图片上滑动。对于每一个窗口,我们想标记每一个中心像素点。
a. 它能够工作,但是不是一个好的idea,因为它的计算非常复杂。b. 非常不高效的。不会重复使用重叠部分的共享特性。所以在训练中,并没有人使用这种方法。

- 将网络设计成一个卷基层,同时对所有像素点进行预测。
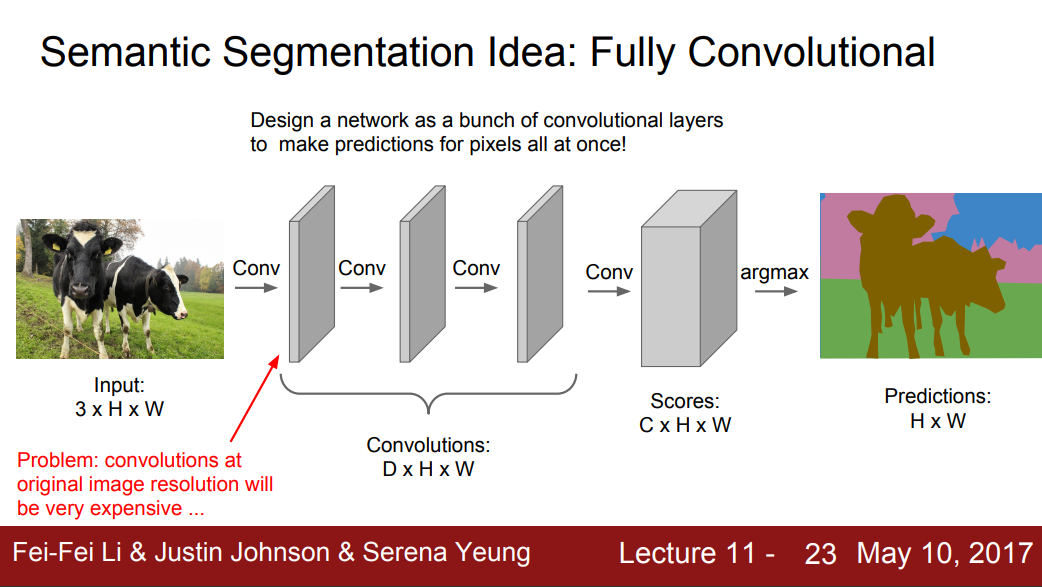
a. 输入是整张image,输出是图片中每一个像素点的标记。
b. 我们需要大量的标记数据,并且这些标记数据是非常昂贵的。
c. 这种方案需要更深的卷积层。
d. 损失函数是每一个像素点的交叉熵损失。
e. 数据增强在这里表现很好。
f. 在原始图像下,这种卷积的生成非常昂贵。
g. 实际上,我们现在还没有看到这样的情况。
- 基于第二种方案,不同点是在网络中采用了下采样与上采样。

图像的上采样与下采样
由于使用整张图片是非常昂贵的。因此首先多个层使用下采样,然后最后使用上采样。
下采样类似于池化操作。上采样类似于”Nearest Neighbor” or “Bed of Nails” or “Max unpooling”。
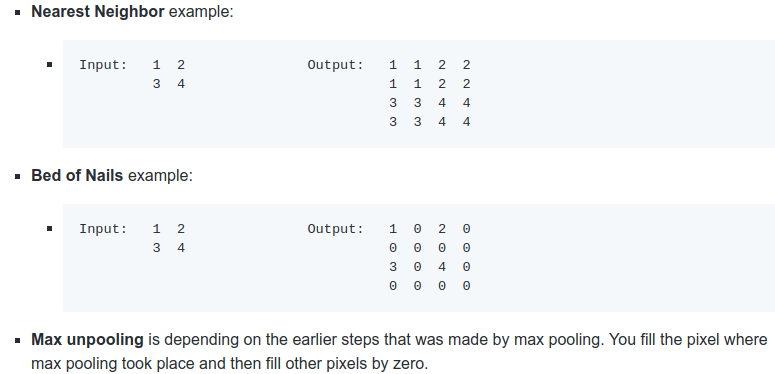
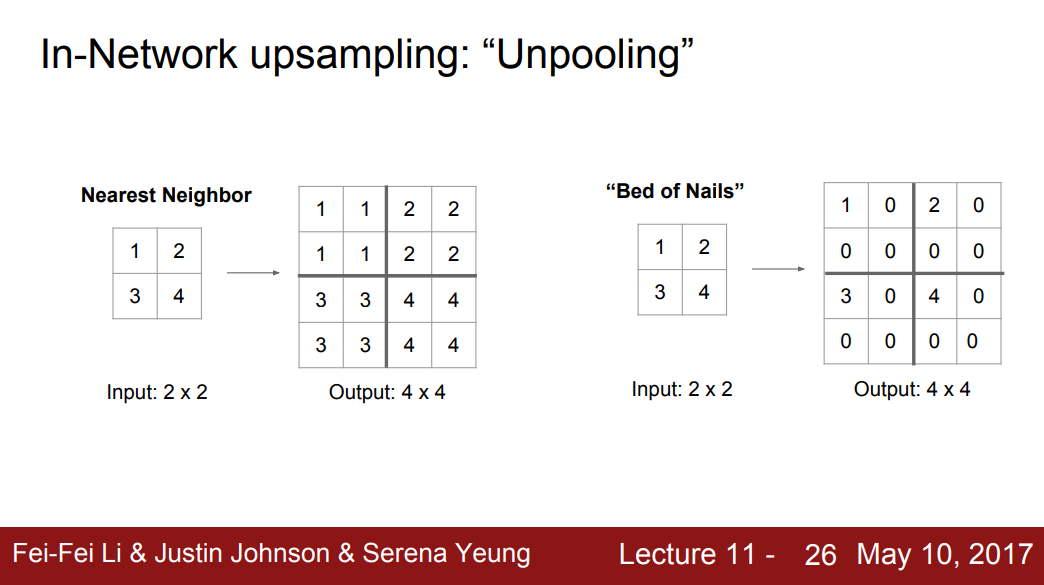
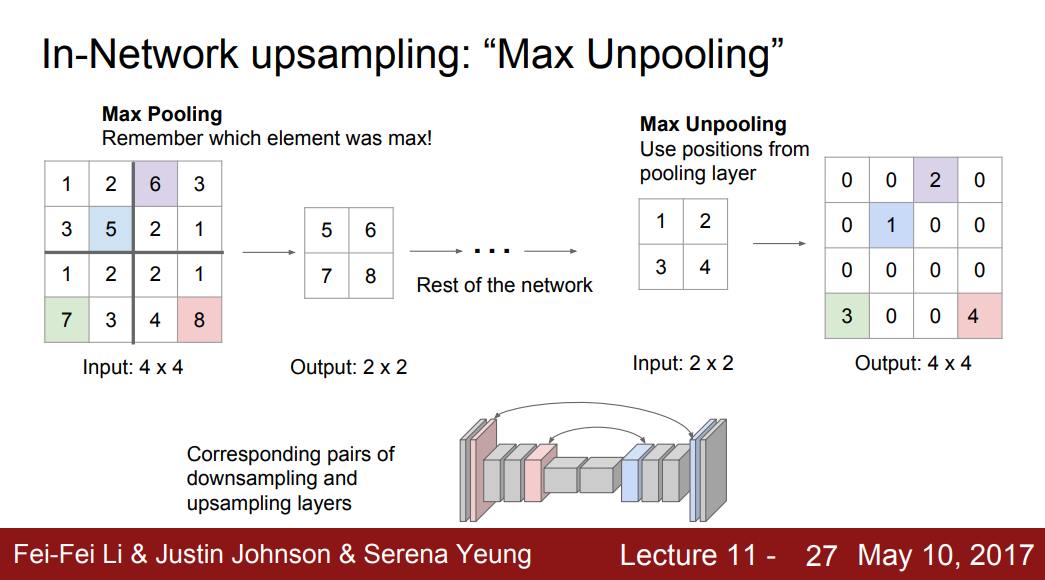
Max unpooling是上采样中最好的方案。
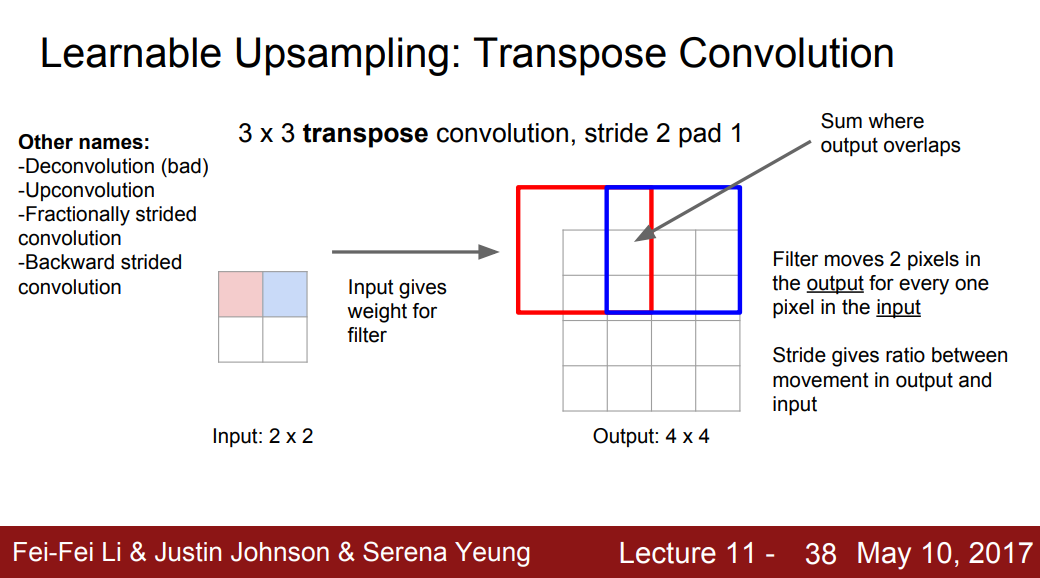
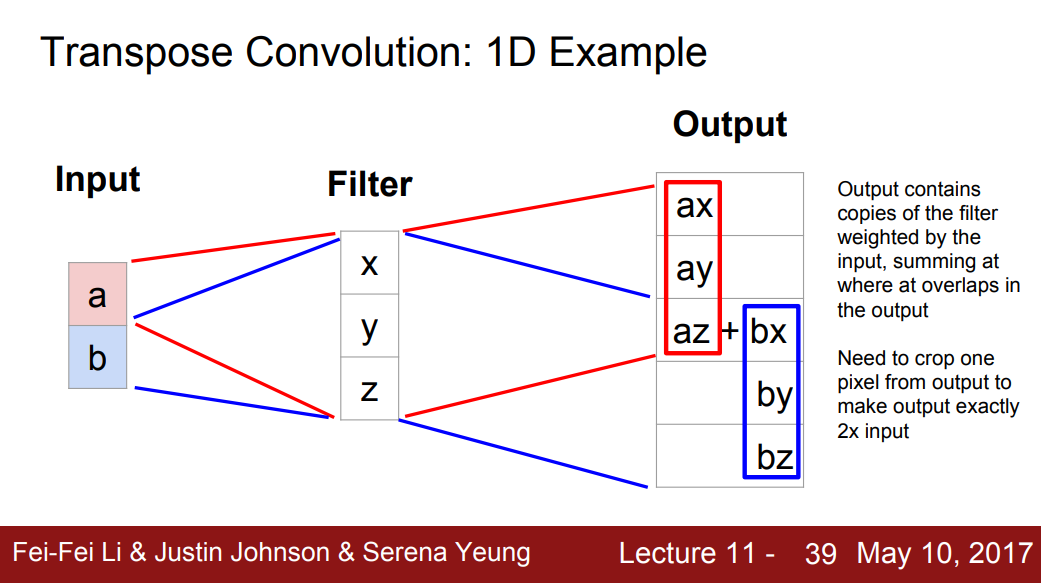
卷积转置